Happy World Backup Day! Here’s a quick little Ansible Role I wrote to automate backup configuration for hordes of servers using Rdiff-Backup from an Ansible inventory file. If you have no idea what I just said you may want to skip to “I’m Confused” at the very bottom of this post.
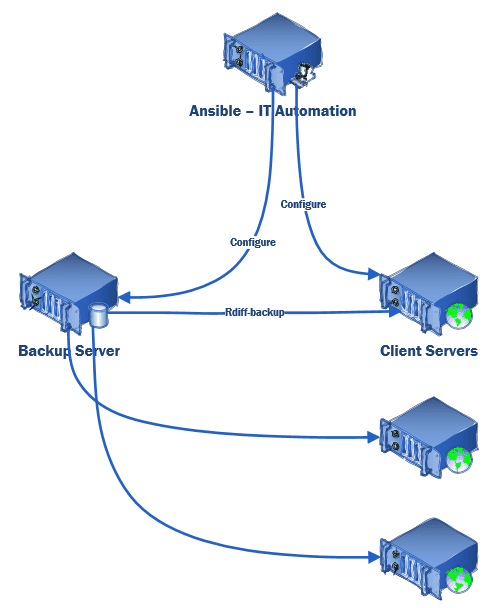
What does the Rdiff-Backup Ansible Role do?
- Creates a folder on the backup storage server to store backups.
- Creates a backup script on the backup server. This script will use rdiff-backup over ssh to backup every server on the list (below) and prune backups older than 1-year (default).
- Adds/removes servers in an Ansible inventory file to a backup list which the backup script calls as servers are provisioned/decommissioned (the script will not delete backups on a decommission, only stop taking them).
- Installs the rdiff-backup program on both the client and backup server.
- Generates an SSH key-pair on the backup server and adds that public key to the authorized key file on each client to allow the backup server to ssh into the clients.
- Scan ssh-key from client and add it to known hosts on backup server
- Create a cron job on the backup server to run the backup script once a day.
The rdiff-backup-script role is available on Ansible Galaxy and I’ve uploaded the source to GitHub under the MIT license.
Requirements
You will need:
- Ansible (best to be installed on it’s own Linux server).
- A Linux server with lots of disk storage to serve as a backup server.
- Lots of Linux servers in your Ansible inventory that need to be backed up.
I have tested this on Ubuntu 16.04, but it should work with any distribution (CentOS, RedHat, Debian, etc.) as long as rdiff-backup is in the repositories available to the package manager.
Install the Rdiff-Backup Script Ansible Role
On your Ansible server install the rdiff-backup-script role with:
ansible-galaxy install ahnooie.rdiff-backup-script
Create a playbook file, rdiff-bakcup-script.yml with the contents:
- hosts: web-servers
roles:
- { role: ahnooie.rdiff-backup-script, rdiff_backup_server: backupserver.example.com }Your Ansible inventory file would look something like this:
[web-servers] servera.example.com serverb.example.com serverc.example.com
Run the playbook with:
ansible-playbook rdiff-backup-script.yml
Once the playbook has run all servers will be configured for backup which will occur at the next cron job run (defaults to 01:43 am).
The above playbook should be added to your site config so it is run automatically with the rest of your Ansible playbooks. It would also be wise to have something like Nagios or Logcheck watch the logs and alert on failures or stale log last modified dates.
The backup script does not try to create an LVM snapshot and then backup the snapshot. That would certainly be cleaner and I may add that ability later. The default settings exclude quite a few files from the backup so make sure those exclusions are what you want. One thing I excluded by default is a lot of LXC files. If you’re using LXC you may want them. Also always test a restore before relying on it.
Obviously, test it in a test environment and make sure you understand what it does before trying it on anything important.
Check your backup strategy
This is a good day to check your backup strategy. A few things to consider:
- System backups are important, not just the data files. You never know what you’re missing in your Document only backups and restoring service from system backups is much faster than rebuilding systems.
- Frequency. If you can’t afford to lose an hour of work backup at least every hour.
- Geographic redundancy. Local fires, hurricanes, fires earthquakes can wipe out multiple locations in cities all at once. Keep at least one backup in a separate part of the globe.
- Versioned backups. On Monday you took a backup. On Tuesday your file got corrupted. On Wednesday you overwrote Monday’s backups with Wednesday’s backup. Enough said.
- Test restoring from your backups (it’s good to test at least once a year on World Backup Day) to make sure they work.
- Encrypt. Make sure your backups to cloud services, insecure locations are encrypted (but also make sure you have provisions to decrypt it when needed).
- Cold storage. Keep at least one backup offline. When a bug in your backup program deletes all your live data and your backups you’ll be glad you did.
- Keep at least 3 copies of data you don’t want to lose. Your live version (obviously), one onsite backup that will allow you to restore quickly, and one offsite backup in a far away state or country.
I’m Confused
You might want to backup your computer. I’d suggest looking at CrashPlan, SpiderOak, or BackBlaze which are all reputable companies that offer automatic cloud backup services for your computer. The main thing you want to look at for pricing is how much data you have vs the number of computers you have. CrashPlan and BackBlaze charge by the computer but offer unlimited data so they would be ideal if you have a lot of data but few computers. SpiderOak lets you have unlimited computers but charges you by how much space you use making it ideal if you have little data and many devices.