
Here are my personal ZFS best practices and naming conventions to structure and manage ZFS data sets.
ZFS Pool Naming
I never give two zpools the same name even if they’re in different servers in case there is the off-chance that sometime down the road I’ll need to import two pools into the same system. I generally like to name my zpool tank[n] where is an incremental number that’s unique across all my servers.
So if I have two servers, say stor1 and stor2 I might have two zpools :
stor1.b3n.org: tank1
stor2.b3n.org: tank2
Top Level ZFS Datasets for Simple Recursive Management
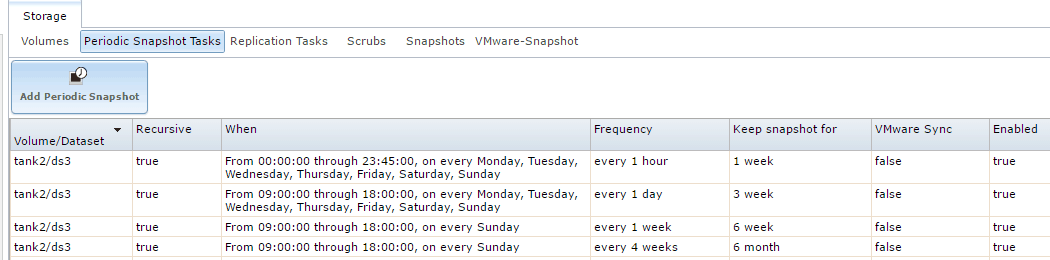
Create a top level dataset called ds[n] where n is unique number across all your pools just in case you ever have to bring two separate datasets onto the same zpool. The reason I like to create one main top-level dataset is it makes it easy to manage high level tasks recursively on all sub-datasets (such as snapshots, replication, backups, etc.). If you have more than a handful of datasets you really don’t want to be configuring replication on every single one individually. So on my first server I have:
tank1/ds1
I usually mount tank/ds1 as readonly from my CrashPlan VM for backups. You can configure snapshot tasks, replication tasks, backups, all at this top level and be done with it.
Name ZFS Datasets for Replication
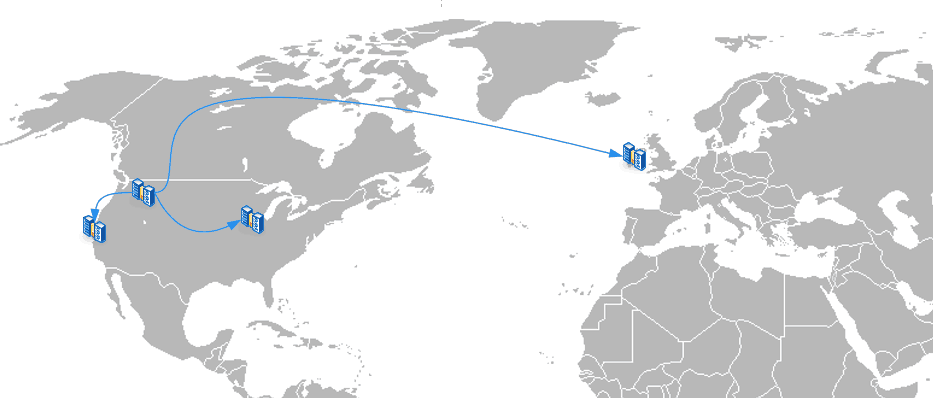
One of the reasons to have a top level dataset is if you’ll ever have two servers…
stor1.b3n.org
| - tank1/ds1
stor2.b3n.org
| - tank2/ds2
I replicate them to each other for backup. Having that top level ds[n] dataset lets me manage ds1 (the primary dataset on the server) completely separately from the replicated dataset (ds2) on stor1.
stor1.b3n.org
| - tank1/ds1
| - tank2/ds2 (replicated)
stor2.b3n.org
| - tank2/ds2
| - tank1/ds1 (replicated)
Advice for Data Hoarders. Overkill for the Rest of Us

The ideal is we backup everything. But in reality storage costs money, WAN bandwidth isn’t always available to backup everything remotely. I like to structure my datasets such that I can manage them by importance. So under the ds[n] dataset create sub-datasets.
stor1.b3n.org
| - tank1/ds1/kirk – very important – family pictures, personal files
| - tank1/ds1/spock – important – ripped media, ISO files, etc.
| - tank1/ds1/redshirt – scratch data, tmp data, testing area
| - tank1/ds1/archive – archived data
| - tank1/ds1/backups – backups
Kirk – Very Important. Family photos, home videos, journal, code, projects, scans, crypto-currency wallets, etc. I like to keep four to five copies of this data using multiple backup methods and multiple locations. It’s backed up to CrashPlan offsite, rsynced to a friend’s remote server, snapshots are replicated to a local ZFS server, plus an annual backup to a local hard drive for cold storage. 3 copies onsite, 2 copies offsite, 2 different file-system types (ZFS, XFS) and 3 different backup technologies (CrashPlan, Rsync, and ZFS replication) . I do not want to lose this data.
Spock – Important. Important data that would be a pain to lose, might cost money to reproduce, but it isn’t catastrophic. If I had to go a few weeks without it I’d be fine. For example, rips of all my movies, downloaded Linux ISO files, Logos library and index, etc. If I lost this data and the house burned down I might have to repurchase my movies and spend a few weeks ripping them again, but I can reproduce the data. For this dataset I want at least 2 copies, everything is backed up offsite to CrashPlan and if I have the space local ZFS snapshots are replicated to a 2nd server giving me 3 copies.

Redshirt – This is my expendable dataset. This might be a staging area to store MakeMKV rips until they’re transcoded, I might do video editing here or test out VMs. This data doesn’t get backed up… I may run snapshots with a short retention policy. Losing this data would mean losing no more than a days worth of work. I might also run zfs sync=disabled to get maximum performance here. And typically I don’t do ZFS snapshot replication to a 2nd server. In many cases it will make sense to pull this out from under the top level ds[n] dataset and have it be by itself.
Backups – Dataset contains backups of workstations, servers, cloud services–I may backup the backups to CrashPlan or some online service and usually that is sufficient as I already have multiple copies elsewhere.
Archive – This is data I no longer use regularly but don’t want to lose. Old school papers that I’ll probably never need again, backup images of old computers, etc. I set set this dataset to compression=gzip9, and back it up to CrashPlan plus a local backup and try to have at least 3 copies.
Now, you don’t have to name the datasets Kirk, Spock, and Redshirt… but the idea is to identify importance so that you’re only managing a few datasets when configuring ZFS snapshots, replication, etc. If you have unlimited cheap storage and bandwidth it may not worth it to do this–but it’s nice to have the option to prioritize.
Now… once I’ve established that hierarchy I start defining my datasets that actually store data which may look something like this:
stor1.b3n.org
| - tank1/ds1/kirk/photos
| - tank1/ds1/kirk/git
| - tank1/ds1/kirk/documents
| - tank1/ds1/kirk/vmware-kirk-nfs
| - tank1/ds1/spock/media
| - tank1/ds1/spock/vmware-spock-nfs
| - tank1/ds1/spock/vmware-iso
| - tank1/ds1/redshirt/raw-rips
| - tank1/ds1/redshirt/tmp
| - tank1/ds1/archive
| - tank1/ds1/archive/2000
| - tank1/ds1/archive/2001
| - tank1/ds1/archive/2002
| - tank1/ds1/backups
| - tank1/ds1/backups/incoming-rsync-backups
| - tank1/ds1/backups/windows
| - tank1/ds1/backups/windows-file-history
With this ZFS hierarchy I can manage everything at the top level of ds1 and just setup the same automatic snapshot, replication, and backups for everything. Or if I need to be more precise I have the ability to handle Kirk, Spock, and Redshirt differently.
I keep coming back to your post as I’m to reorganize my data for the better. Is the top-level dataset, “ds1” under the tank1 vol in FreeNAS kind of redundant? It seems (at least in FreeNAS 11) that when you create the volume it becomes it’s own top-level dataset where you can set properties and take snapshots recursively. To better describe what I’m saying, after I created a new volume “vol2”, it shows up on the Storage page in the Web UI like this:
vol2
-vol2
vol2 also shows up in “zfs list” on the cli.
The top-level vol2 lets you do things like detach, scrub, and volume stats. The lower one lets you change permissions, take snapshots, edit options, and create nested datasets. From here I intend to create nested datasets for archive, backup, vm, media, etc. with more granular control. I’m actually defining my backup strategy from here at this level, and probably won’t replicate at the top-level unless I was migrating to a new system.
Am I missing something else having an additional level of hierarchy like your “ds” under tank?
Hi, Jonathan. Good question. The only reason for the extra top-level dataset is to help with two-way replication between two servers where you want to manage everything at a high level. If on server A I have vol1 and 10 datasets directly under it, and on Server B I have the same, and I want to replicate all datasets from A to B and B to A I will risk naming collisions on the datasets (unless I was careful) but also I’d have to manage replication on a per dataset instead of at the top level (if I set replication on a per volume level than the replicated datasets from server A to B would then try to replicate back to A but would fail because they already exist…). If you tend to not do things at a high level and more on a per-dataset level then eliminating it, like you suggest should be fine.
I just wanted to say thanks for this post! I recently moved over to using TruNAS and have decided that I didn’t like my first setup which I’m sure comes a major shock to everyone.
I really like your idea of breaking down my data into logical chunks based on backup priority. I am going to do something very similar because as you point out there is some data that should be backed up to multiple places and this makes it easy to do.
Hi, Joel! Glad to hear it was helpful.
On Truenas Scale, I can directly select tank1 as a snapshot source, so is the advice for creating a ds[n] redundant now?
A late reply, but in case anyone is thinking the same – I would say yes.
The root dataset is still a bit of a ‘special case’. It can contain hidden directories and whilst the option is there to encrypt it, it’s advised not to do so in the documentation.
So if you want to encrypt everything and have that encryption inherited from a parent dataset, creating a top-level dataset just for this purpose and leaving the root dataset unencrypted is the way to go.
https://www.truenas.com/docs/scale/25.04/scaleuireference/datasets/encryptionuiscale/
“The Encryption option on the Pool Manager screen sets encryption for the pool and root dataset. Pool-level encryption is not recommended”
Thanks, sven. I was considering encrypting at the root level on my next box so I’m glad you mentioned that. It seems it’s just better to not do too many things at the root level.